分布式ID生成器解决方案SnowflakeX
一、前言
什么情况下我们需要ID生成器?
- 数据库水平拆分的情况下,主键由于需要作为业务标识使用,需要唯一。
- 业务编号需要暴露给用户,但是又不想被用户猜到需要被隐藏的业务编号
- 业务编号需要体现业务信息,比如订单分类订单渠道等等
本次解决方案主要应对的场景是?
- 数据库水平拆分的情况下,主键由于需要作为业务标识使用,需要唯一。
本次的ID生成器设计目标?
- 全局唯一
- 每秒可生成100W+
- 趋于递增(对索引友好)
- 高可用
- 可伸缩
二、常见ID生成方案
1、UUID方案
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分
UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为1632=2128,约等于3.4 x 1038。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的32个字符。示例:
550e8400-e29b-41d4-a716-446655440000
每秒产生10亿笔UUID,100年后只产生一次重复的机率是50%
优点:
- 本地生成,没有网络消耗
- 可以任意水平扩展
- 生成效率高
- 生成节点不限
缺点
- 128bit,占用空间大
- 无法做到趋势递增
- 索引效率差
2、数据库自增列方案
可以通过设置bigint类型的数据库自增列,在事务中通过Insert操作获取主键Id
表结构:
| 列 | 数据类型 | 说明 |
|---|---|---|
| id | bigint | 主键,自增列 |
| v | int | 用来辅助进行Insert操作 |
- MySQL语法
START TRANSACTION;
INSERT INTO sequence(v) VALUES(0);
SELECT LAST_INSERT_ID();
ROLLBACK;
- SQL Server语法
BEGIN TRANSACTION;
INSERT INTO sequence(v) VALUES(0);
SELECT @@IDENTITY;
ROLLBACK;
测试情况:
测试机:Intel 志强E3 4核,16GB内存
数据库:SQL Server 2012 开发版
测试结果:生成10万ID大约3秒
优点
- 可以实现ID完全递增
- 部署简单,有DB就可以
缺点
- 生成效率差,取决于数据库性能指标,每秒生成一万ID都很难
- 依赖于数据库,如果DB发生故障,在做主从切换的时候可能会引发BUG
基于数据库生成ID的方案有很多,这是最简单的一种
3、Snowflake方案
snowflake的核心思想就是采用bigint作为id生成类型,并将所占的64bit划分成多段
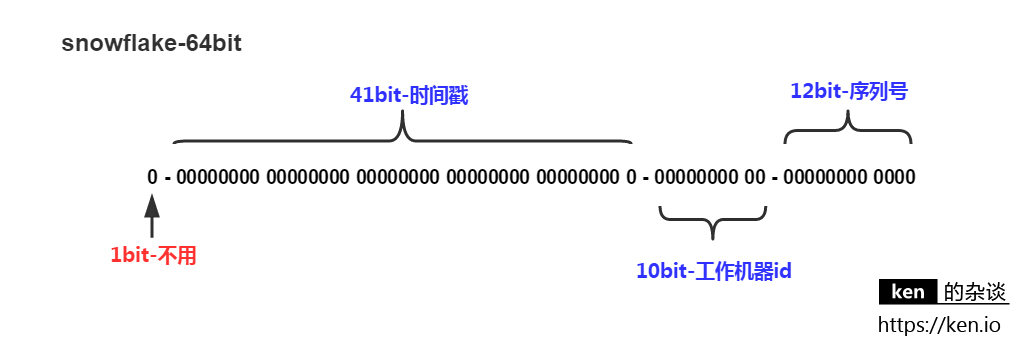
| 分段 | 作用 | 说明 |
|---|---|---|
| 1bit | 保留 | — |
| 41bit | 时间戳,精确到毫秒 | 可以支持69年的跨度 |
| 5bit | DatacenterId | 可以最多支持32个节点 |
| 5bit | WorkerId | 可以最多支持32个节点 |
| 12bit | 毫秒内的计数 | 支持每个节点每毫秒产生4096个ID |
理论上单机每秒400W+,最多每秒可以生成41亿+的ID
核心运算逻辑:
##右移运算&位运算
(timestamp << 22) | (datacenterId << 17) | (workerId << 12) | sequence;
优点
- ID趋势递增
- 生成效率高,单机每秒400W+
- 支持线性扩充
- 稳定性高,不依赖DB等服务
缺点
- 依赖服务器时间,如果服务器时间发生回拨,可能导致生成重复ID
三、综合方案(SnowflakeX)
基于snowflake方案,引入时间回拨保护机制,形成趋于完美的方案
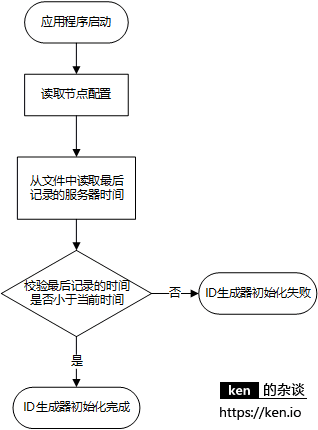
应用启动校验流程(新增)
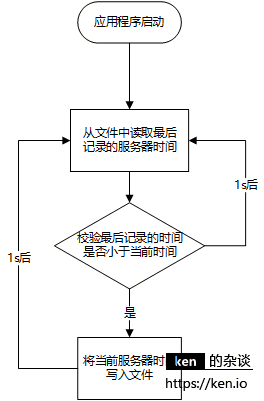
时间打点机制(新增)
ID生成时时间校验机制(原有)
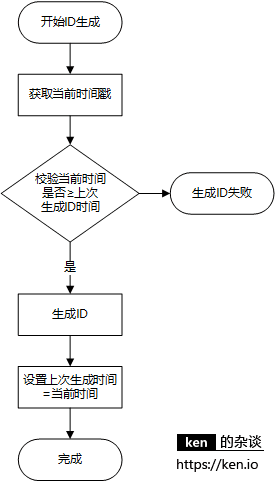
通过这三种保障机制,不管是程序运行时服务器时间发生了回拨,
还是说应用down机的同时,发生了时间回拨等恶劣情况,都可以保证生成的ID不重复
不过,虽然理论上每秒单机可以生成400W+的ID,实际在使用过程中,如果中心化部署,通过API的方式来使用,还要考虑到实际的网络消耗。
测试情况:
测试机1台: Intel 2.30GHz 双核 虚拟机 百兆网卡
测试结果:通过HTTP API每秒可获取100W的ID
四、方案对比
| 方案 | 唯一性 | 每秒100W+ | 趋于递增 | 高可用 | 可伸缩 |
|---|---|---|---|---|---|
| UUID | 基本满足 | 满足 | 不满足 | 满足 | 满足 |
| 数据库自增列 | 满足 | 不满足 | 满足 | 基本满足 | 不满足 |
| Snowflake | 基本满足 | 满足 | 满足 | 满足 | 满足 |
| SnowflakeX | 满足 | 满足 | 满足 | 满足 | 满足 |