Hadoop高可用集群部署指南
一、前言
1、Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算能力。
https://baike.baidu.com/item/Hadoop/3526507
2、Hadoop应用场景
- 大数据量存储:分布式存储(比如各种云存储)
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 数据分析: 可以基于Hadoop+HBase构建实时数据分析系统
二、准备工作
1、集群节点规划
| 机器名 | IP | 节点应用 |
|---|---|---|
| hdfs01 | 192.168.88.91 | hadoop |
| hdfs02 | 192.168.88.92 | hadoop |
| hdfs03 | 192.168.88.93 | hadoop |
| zknode1 | 192.168.88.11 | ZooKeeper |
| zknode2 | 192.168.88.12 | ZooKeeper |
| zknode3 | 192.168.88.13 | ZooKeeper |
2、软件环境说明
| 项 | 说明 |
|---|---|
| Linux Server | CentOS 7 |
| JDK | 1.8.0 |
| ZooKeeper | 3.4.11 |
| Hadoop | 3.0.0 |
3、基础环境准备
- CentOS7虚拟机安装
Hyper-V下安装CentOSx虚拟机:https://ken.io/note/hyper-v-course-setup-centos
参考以上文章部署6台CentOS虚拟机
- JDK1.8部署
CentOS下JDK部署:https://ken.io/note/centos-java-setup
参考以上文章为每台虚拟机部署JDK8
4、ZooKeeper集群部署
- 为什么要部署ZooKeeper
可以通过ZooKKeeper完成Hadoop NameNode的监控,发生故障时做到自动切换,从而达到高可用
- 部署指引&要求
基于CentOS7部署ZooKeeper集群:https://ken.io/note/zookeeper-cluster-deploy-guide
参考以上文章部署以下ZooKeeper集群
| 机器名 | IP | 节点应用 |
|---|---|---|
| zknode1 | 192.168.88.11 | ZooKeeper |
| zknode2 | 192.168.88.12 | ZooKeeper |
| zknode3 | 192.168.88.13 | ZooKeeper |
5、Hadoop节点系统设置调整
本小结配置只针对Hadoop节点
- 机器名修改
#hdfs01
hostnamectl set-hostname hdfs01.hdfscluster
#hdfs02
hostnamectl set-hostname hdfs02.hdfscluster
#hdfs03
hostnamectl set-hostname hdfs03.hdfscluster
参考:https://ken.io/note/centos-hostname-setup
- 配置hosts
#修改hosts文件
vi /etc/hosts
#增加以下配置
192.168.88.91 hdfs01 hdfs01.hdfscluster
192.168.88.92 hdfs02 hdfs02.hdfscluster
192.168.88.93 hdfs03 hdfs03.hdfscluster
- 关闭防火墙
#关闭防火墙
systemctl stop firewalld
#禁用防火墙开机启动
systemctl disable firewalld
- 关闭SELinux
因为 Hadoop 的启动需要使用 SSH,如果 SELinux 处于开启状态,默认情况下无法完成SSH的免密登录。最简单的做法就是关闭SELinux
#1、关闭SELinux:
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
#2、重启:
reboot
6、Hadoop节点SSH免密登录准备
- 在Master节点生成密钥
通过ssh-keygen -t rsa命令生成密钥,一直回车即可
(此操作在hdfs01节点进行)
#生成密钥
ssh-keygen -t rsa
#查看公钥内容
cat ~/.ssh/id_rsa.pub
- Master到Slave的SSH无密码登录
在Slave节点创建~/.ssh/authorized_keys文件
并将Master节点~/.ssh/id_rsa.pub中的内容写入保存
在hdfs02、hdfs03节点进行如下操作cd
#创建ssh文件夹
mkdir ~/.ssh
#创建ssh授权密钥文件
vi ~/.ssh/authorized_keys
#写入Master节点~/.ssh/id_rsa.pub中的内容
- SSH免密登录测试
[root@hdfs01 ~]# ssh 192.168.88.92
The authenticity of host '192.168.88.92 (192.168.88.92)' can't be established.
ECDSA key fingerprint is 59:12:85:3f:ed:67:2c:09:e4:61:25:1c:d8:d4:e5:fd.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.88.92' (ECDSA) to the list of known hosts.
Last login: Mon Mar 12 18:18:16 2018 from 192.168.88.1
[root@hdfs02 ~]#
#退出登录
logout
三、Hadoop集群部署
1、下载Hadoop软件包&部署准备
- 下载最新版Hadoop
官方Hadoop镜像包下载地址:http://mirrors.shu.edu.cn/apache/hadoop/common/
本次我们选用的是3.0.0版本
#进入下载目录
cd /home/download
#下载Hadoop
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
#解压到指定目录
mkdir /usr/hdfs
tar -zvxf hadoop-3.0.0.tar.gz -C /usr/hdfs
- 创建Hadoop相关目录
mkdir /hadoop
mkdir /hadoop/data
mkdir /hadoop/name
mkdir /hadoop/tmp
mkdir /hadoop/log
mkdir /hadoop/checkpoint
mkdir /hadoop/journalnode
目录作用说明
| 目录 | 说明 |
|---|---|
| /hadoop | 存储hadoop数据 |
| /hadoop/data | 存储DataNode数据 |
| /hadoop/name | 存储NameNode数据 |
| /hadoop/tmp | 存储临时文件 |
| /hadoop/log | 存储日志 |
| /hadoop/checkpoint | 存储NameNode的CheckPoint数据 |
| /hadoop/journalnode | 存储JournalNode数据 |
2、配置Hadoop
- 配置Hadoop环境变量
#修改环境变量
vi /etc/profile
#增加以下内容
export HADOOP_HOME=/usr/hdfs/hadoop-3.0.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#使环境变量生效
source /etc/profile
hadoop的配置文件位于/usr/hdfs/hadoop-3.0.0/etc/hadoop下。
既然我们已经配置了环境变量,后续均已$HADOOP_HOME替代/usr/hdfs/hadoop-3.0.0
- 配置JDK环境变量
#修改文件
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
#增加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_161
- 修改core-site.xml
用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录以及用于rack-aware集群中的配置文件的配置等
修改配置文件:
vi $HADOOP_HOME/etc/hadoop/core-site.xml
更改为以下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfscluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/hadoop/journalnode</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.88.11:2181,192.168.88.12:2181,192.168.88.13:2181</value>
</property>
</configuration>
- 修改hdfs-site.xml
HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限等
修改文件
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
更改为以下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/hadoop/checkpoint</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>10</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hdfscluster</value>
</property>
<property>
<name>dfs.ha.namenodes.hdfscluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn1</name>
<value>hdfs01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn2</name>
<value>hdfs02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfscluster.nn1</name>
<value>hdfs01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfscluster.nn2</name>
<value>hdfs02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdfs01:8485;hdfs02:8485;hdfs03:8485/hdfscluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
</configuration>
- 修改mapred-site.xml
HDFS的相关设定,如reduce任务的默认个数、任务所能够使用内存的默认上下限等
修改文件:
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
修改为以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改yarn-site.xml
修改文件:
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
修改为以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hdfscluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdfs02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdfs03</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hdfs02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hdfs03:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.88.11:2181,192.168.88.12:2181,192.168.88.13:2181</value>
</property>
</configuration>
- 配置slave节点
创建文件:
vi $HADOOP_HOME/etc/hadoop/slaves
写入以下内容:
hdfs02
hdfs03
- 配置log4j日志
根据需要修改log4j的日志保存路径,以及日志输出的粒度
vi $HADOOP_HOME/etc/hadoop/log4j.properties
# 修改日志的路径
hadoop.log.dir=/hadoop/log
3、Hadoop初始化&顺序启动
- Hadoop初始化&启动
# 启动 journalnode(hdfs01,hdfs02,hdfs03)
hdfs journalnode
# 格式化 namenode(hdfs01)
hdfs namenode -format
# 初始化 HA 状态到 zk(hdfs01)
hdfs zkfc -formatZK
# 启动 namenode active(hdfs01)
hdfs namenode
# 同步 namenode(hdfs02)
hdfs namenode -bootstrapStandby
# 启动 namenode standby(hdfs02)
hdfs namenode
# 启动ZookeeperFailoverController(hdfs01,hdfs02)
hdfs zkfc
# 启动 datanode(hdfs02,hdfs03)
hdfs datanode
# 启动 resourcemanager(hdfs02,hdfs03)
yarn resourcemanager
# 启动 nodemanager(hdfs02,hdfs03)
yarn nodemanager
- 启动后在各个节点查看进程运行情况
#hdfs01
[root@hdfs01 ~]# jps
12452 JournalNode
12772 DFSZKFailoverController
12884 Jps
12540 NameNode
#hdfs02
[root@hdfs02 ~]# jps
13457 NameNode
13667 DataNode
13590 DFSZKFailoverController
13367 JournalNode
13799 ResourceManager
14281 Jps
14079 NodeManager
#hdfs03
[root@hdfs03 ~]# jps
12580 DataNode
12490 JournalNode
12972 Jps
12798 NodeManager
12703 ResourceManager
- 顺序启动备忘
Hadoop集群启动过一次之后,就不需要再进行fomat等操作了,另外正常启动过一次之后,就不要关注启动的输出信息了,可以使用nohup命令,启动更方便。后续正常启动顺序:
# 启动 journalnode(hdfs01,hdfs02,hdfs03)
nohup hdfs journalnode &
# 启动 namenode active(hdfs01)
nohup hdfs namenode &
# 启动 namenode standby(hdfs02)
nohup hdfs namenode &
# 启动ZookeeperFailoverController(hdfs01,hdfs02)
nohup hdfs zkfc &
# 启动 datanode(hdfs02,hdfs03)
nohup hdfs datanode &
# 启动 resourcemanager(hdfs02,hdfs03)
nohup yarn resourcemanager &
# 启动 nodemanager(hdfs02,hdfs03)
nohup yarn nodemanager &
#启动完成之后使用jps命令查看各节点服务是否正常启动即可
jps
四、Hadoop集群管理测试
1、集群状态查看
- NameNode状态
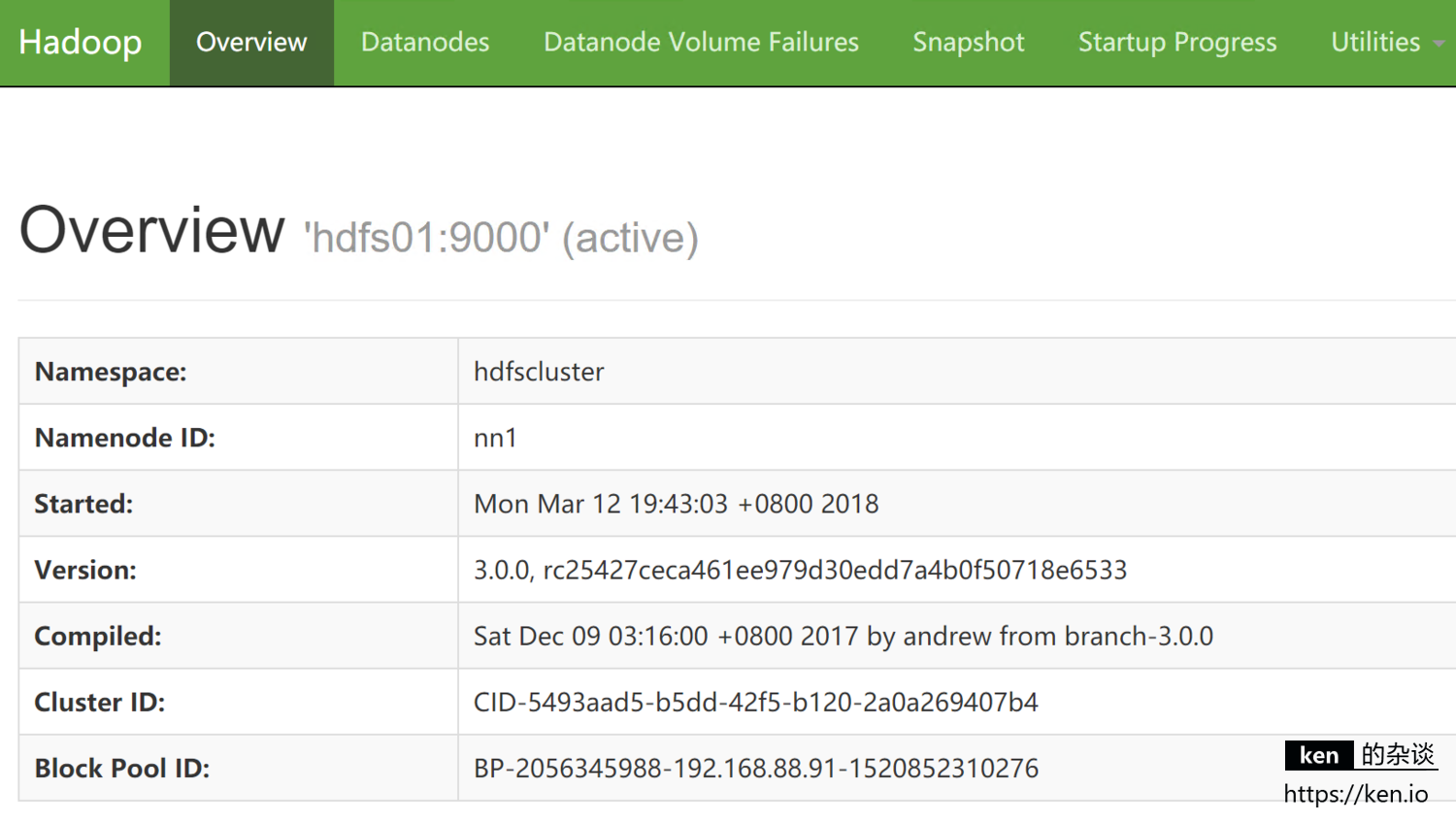
NameNode(Active)节点:http://192.168.88.91:50070
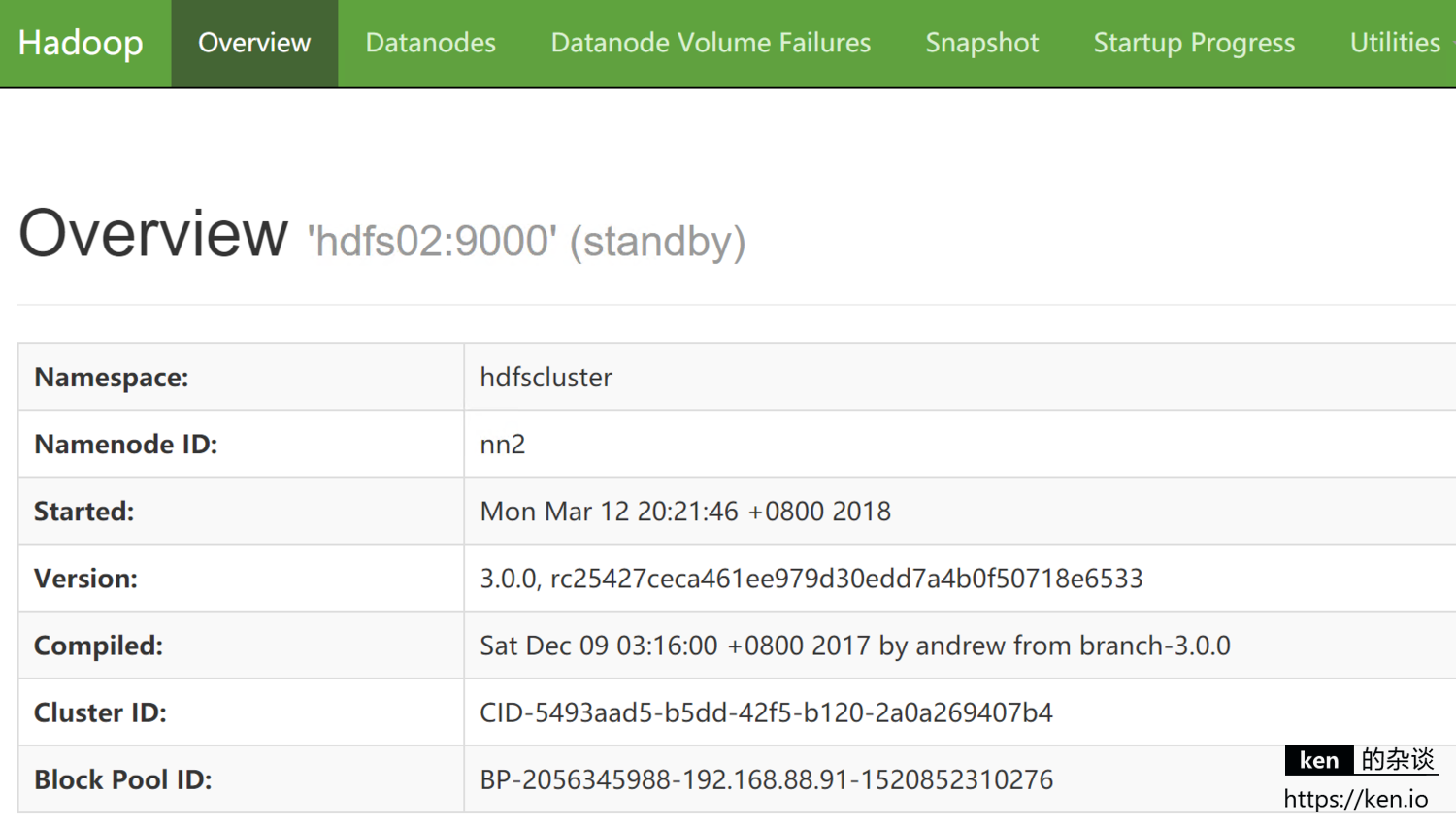
NameNode(Standby)节点:http://192.168.88.92:50070
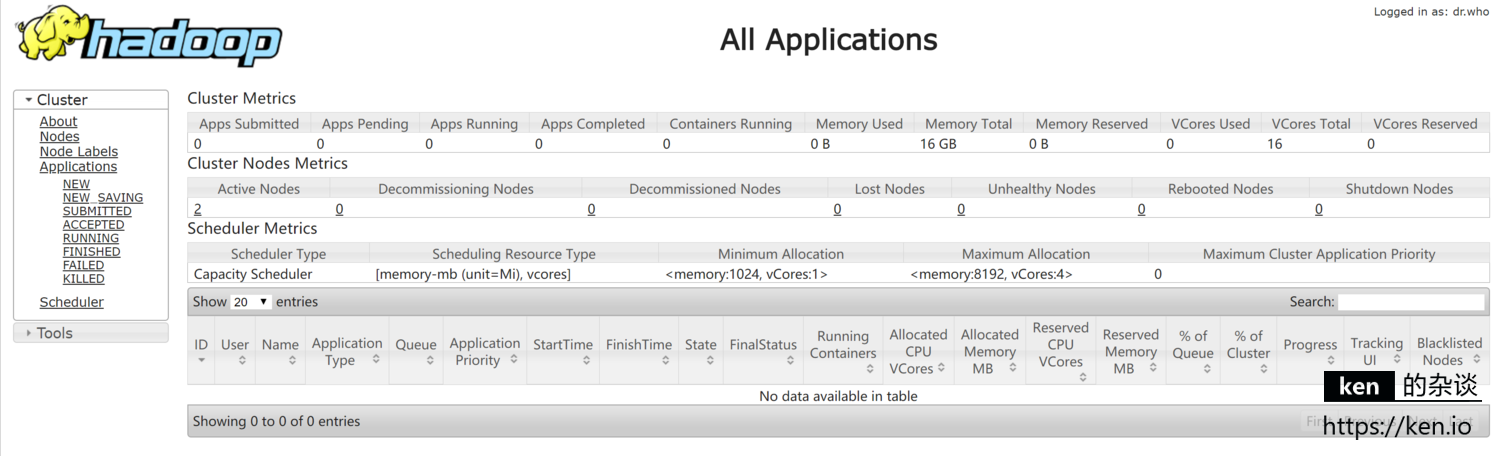
- ResourceManager状态
2、NameNode高可用测试
当前 hdfs01 的NameNode是active状态,hdfs02 的NameNode是standby状态
这里直接结束hdfs01节点NameNode的进程进行测试
- 结束NameNode(Active)节点进程
[root@hdfs01 ~]# jps
12452 JournalNode
12772 DFSZKFailoverController
12540 NameNode
13166 Jps
[root@hdfs01 ~]# kill 12540
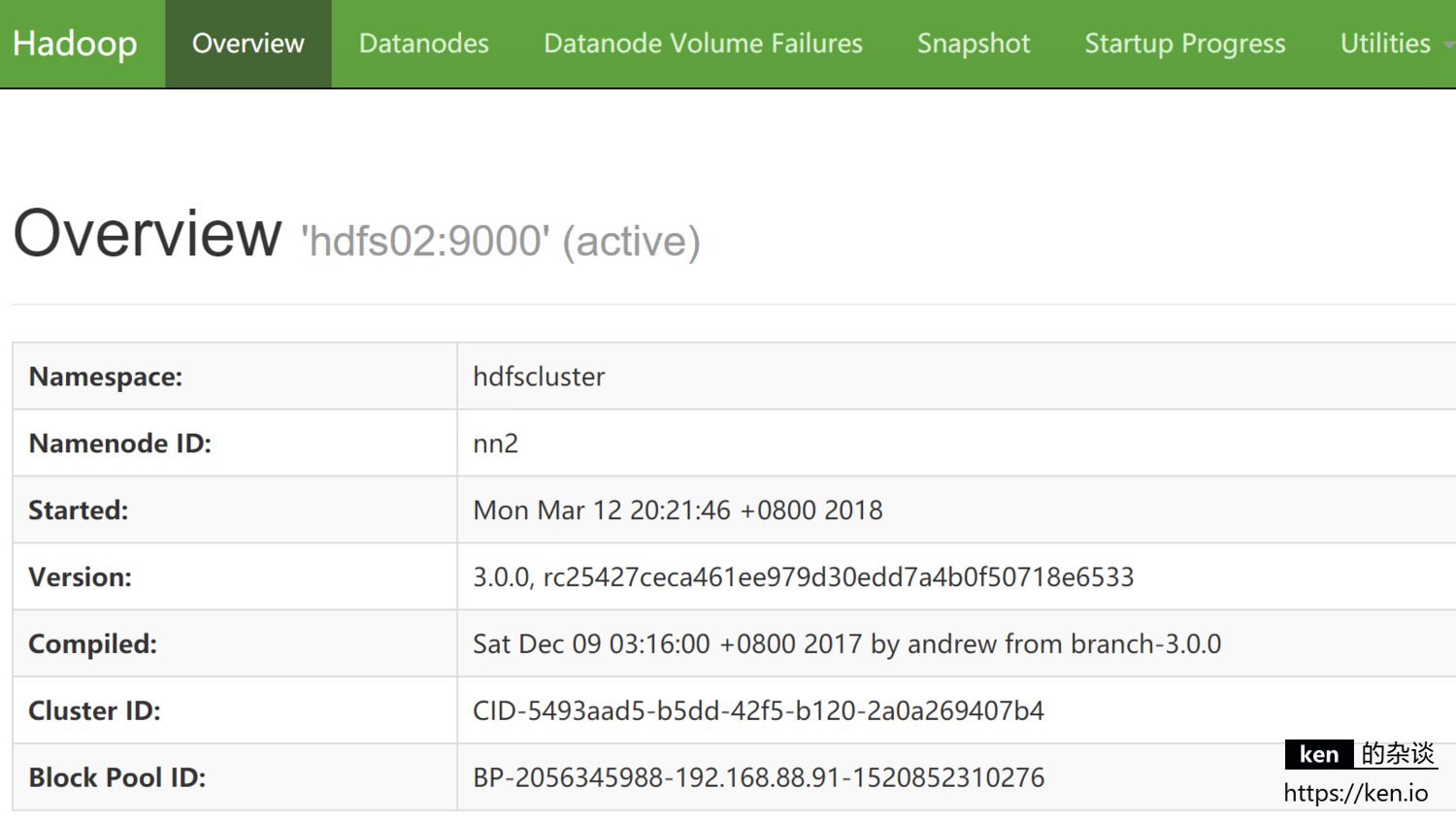
- 查看Standy节点(HDFS02)状态
在hdfs01节点NameNode服务挂掉之后,hdfs02 的NameNode自动切换到了active状态
五、Hadoop配置项说明
1、core-site.xml配置项说明
| 配置项 | 说明 |
|---|---|
| fs.defaultFS | 表示集群NameNode的Namespace,也是NameNodeCluster ID |
| dfs.journalnode.edits.dir | 表示journalnode的数据文件路径 |
| hadoop.tmp.dir | 临时文件路径 |
| fs.trash.interval | 表示回收站的保留时间(分钟),也即hdfs的文件删除后,在回收站里面保留的时长 |
| io.file.buffer.size | 表示读取文件的字节数(byte) |
| ha.zookeeper.quorum | 表示zookeeper集群的主机与端口 |
2、hdfs-site.xml配置项说明
| 配置项 | 说明 |
|---|---|
| dfs.replication | 表示hdfs的数据块备份数量,默认是3 |
| dfs.namenode.name.dir | NameNode数据目录 |
| dfs.datanode.data.dir | DataNode数据目录 |
| dfs.namenode.checkpoint.dir | checkpoint数据目录 |
| dfs.blocksize | 表示数据块的大小,默认为64M,可根据需要改为128M,甚至256M |
| dfs.namenode.handler.count | NameNode进程数 |
| dfs.datanode.handler.count | DataNode进程数 |
| dfs.nameservices | NameNode集群ID,跟core-size.xml配置项fs.defaultFS保持一致 |
| dfs.ha.namenodes.hdfscluster | 表示NameNode各节点的ID,配置两个NameNode节点为例,命名为nn1、nn2,后需要以此ID配置各节点属性 |
| dfs.namenode.rpc-address.hdfscluster.nn1 | 配置nn1节点的远程访问地址和端口 |
| dfs.namenode.rpc-address.hdfscluster.nn2 | 配置nn2节点的远程访问地址和端口 |
| dfs.namenode.http-address.hdfscluster.nn1 | 配置nn1节点的http访问地址和端口 |
| dfs.namenode.http-address.hdfscluster.nn2 | 配置nn1节点的http访问地址和端口 |
| dfs.namenode.shared.edits.dir | NameNode共享的元数据路径,在配置HA时,使用journalnode来保存元数据,维持NameNode元数据的一致性 |
| dfs.client.failover.proxy.provider | 表示HDFS客户端连接到Active NameNode的一个java类(默认) |
| dfs.ha.automatic-failover.enabled | 表示当namenode ha的active namenode出现故障时,是否自动切换 |
| dfs.ha.fencing.methods | 表示故障时自动切换使用的方法 |
3、yarn-site.xml配置项说明
| 配置项 | 说明 |
|---|---|
| yarn.nodemanager.aux-services | NodeManager上运行的附属服务,需配置成mapreduce_shuffle,才可运行MapReduce程序,否则会报错 |
| yarn.resourcemanager.ha.enabled | resourcemanager HA高可用 |
| yarn.resourcemanager.cluster-id | resourcemanager的集群ID,不要与别的集群混淆即可,这里命名为hdfscluster |
| yarn.resourcemanager.ha.rm-ids | resourcemanager的节点ID,以配置两个节点为例,使用rm1,rm2作为ID,后需要以此ID配置各节点属性 |
| yarn.resourcemanager.hostname.rm1 | 配置resourcemanager的rm1节点地址 |
| yarn.resourcemanager.hostname.rm2 | 配置resourcemanager的rm2节点地址 |
| yarn.resourcemanager.webapp.address.rm1 | 配置rm1节点网页访问地址和端口 |
| yarn.resourcemanager.webapp.address.rm2 | 配置rm2节点网页访问地址和端口 |
| yarn.resourcemanager.zk-address | 配置zookeeper来协助管理resourcemanager主备的zookeeper集群主机与端口 |