语雀文档批量导出为Markdown文件
一、前言
语雀的定位由之前的社区转向工具,也不提供批量导出Markdown的功能,有开发者提供了导出脚本可以通过语雀官方API帮我们把文档批量导出为Markdown,方便我们把文档导入notion等其他平台或者备份在本地,以备不时之需
环境依赖
| 工具 | 版本要求 | 本文环境 |
|---|---|---|
| 操作系统 | macOS/Windows/Linux | Windows 11 |
| Python | 3.x | 3.11 |
| pip | from python 3.x | pip 22.3.1 from python 3.11 |
二、操作步骤
1、创建Token
登录语雀后在账户设置中可以创建Token,供访问API使用:https://www.yuque.com/settings/tokens/new
根据最小授权原则,这里只授予读取知识库以及文档的权限即可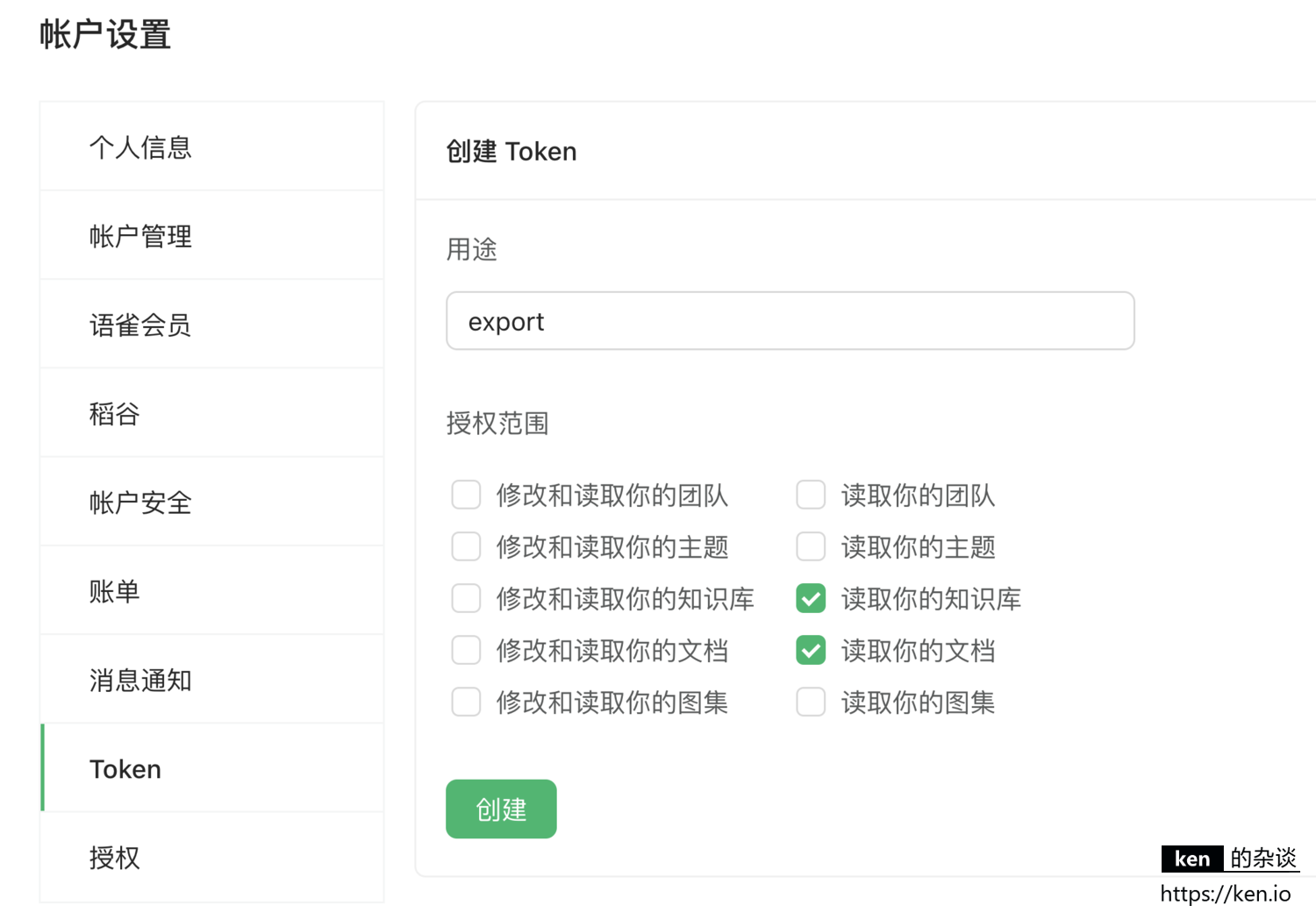
2、安装Python
访问官网,下载自己操作系统对应的Python3 https://www.python.org/downloads/
查看版本
python -V
#输出内容
Python 3.11.0
#如果输出的是Python 2.x,可以使用Python3 -v查看
#后续依赖安装也要使用pip3命令
4、安装依赖
通过pip(Python内置包管理工具)安装代码所需依赖
pip install requests psutil
#输出内容
Collecting requests
Downloading requests-2.28.1-py3-none-any.whl (62 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 62.8/62.8 kB 1.1 MB/s eta 0:00:00
Collecting psutil
Downloading psutil-5.9.4-cp36-abi3-win_amd64.whl (252 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 252.5/252.5 kB 2.6 MB/s eta 0:00:00
###省略其他依赖安装内容###
Installing collected packages: urllib3, psutil, idna, charset-normalizer, certifi, requests
Successfully installed certifi-2022.9.24 charset-normalizer-2.1.1 idna-3.4 psutil-5.9.4 requests-2.28.1 urllib3-1.26.13
5、代码及配置
创建导出目录,例如:d:\yuque,~/yuque
1、创建配置文件config.json
{
"TOKEN": "your token",
"USER_AGENT": "yuque_export",
"BASE_URL": "https://customspace.yuque.com/api/v2",
"DATA_PATH": "yuque_data"
}
| 配置项 | 说明 |
|---|---|
| TOKEN | 替换为前面创建的Token |
| USER_AGENT | 保持默认即可,无需调整 |
| BASE_URL | 语雀官方API地址,无误调整 |
| DATA_PATH | 文档导出目录,无需调整,会在导出目录中创建子目录 |
2、创建Python脚本yuque.py
import json
import sys
import os
import re
import requests
import psutil
from datetime import datetime
if getattr(sys, 'frozen', False):
APPLICATION_PATH = os.path.dirname(sys.executable)
else:
APPLICATION_PATH = os.path.dirname('.')
print(APPLICATION_PATH)
jsonConfig = json.load(open(os.path.join(APPLICATION_PATH, "config.json"), encoding='utf-8'))
class ExportYueQueDoc:
def __init__(self):
try:
if getattr(sys, 'frozen', False):
APPLICATION_PATH = os.path.dirname(sys.executable)
else:
APPLICATION_PATH = os.path.dirname('.')
self.jsonConfig = json.load(open(os.path.join(APPLICATION_PATH, "config.json"), encoding='utf-8'))
self.base_url = self.jsonConfig['BASE_URL']
self.token = self.jsonConfig['TOKEN']
self.headers = {
"User-Agent": self.jsonConfig['USER_AGENT'],
"X-Auth-Token": self.jsonConfig['TOKEN']
}
self.data_path = self.jsonConfig['DATA_PATH']
except:
raise ValueError("config.json 有误")
def get_user_info(self):
res_obj = requests.get(url=self.base_url + '/user', headers=self.headers)
if res_obj.status_code != 200:
raise ValueError("Token 信息错误")
user_json = res_obj.json()
self.login_id = user_json['data']['login']
self.uid = user_json['data']['id']
self.username = user_json['data']['name']
print("=========== 用户信息初始化成功 ==========")
def get_repos_data(self):
repos_json = requests.get(self.base_url + '/users/' + self.login_id + '/repos', headers=self.headers).json()
repos_list = []
for item in repos_json['data']:
rid = item['id'] # 知识库id
name = item['name'] # 知识库名称
repos_list.append({"rid": rid, "repos_name": name})
return repos_list
def get_article_data(self, repos_list):
"""获取文章数据"""
article_list = []
for repos in repos_list:
article_datas = requests.get(self.base_url + '/repos/' + str(repos['rid']) + '/docs',
headers=self.headers).json()
for item in article_datas['data']:
bid = repos['rid']
title = item['title'] # 文章标题
desc = item['description']
slug = item['slug']
article_list.append(
{"bid": bid, "title": title, "desc": desc, "slug": slug, "repos_name": repos["repos_name"]})
for item in article_list:
per_article_data = requests.get(self.base_url + '/repos/' + str(item['bid']) + '/docs/' + item['slug'],
headers=self.headers).json()
posts_text = re.sub(r'\\n', "\n", per_article_data['data']['body'])
result = re.sub(r'<a name="(.*)"></a>', "", posts_text)
# all_datas.append({"title": item['title'], "content": result})
yield result, item["repos_name"], item['title']
def save_article(self, result, repos_name, title):
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
dir_path = f"{self.data_path}/{repos_name}"
dir_path = dir_path.replace(".","_")
filepath = dir_path + f"/{title}.md"
dir_ret = os.path.exists(dir_path)
if not dir_ret:
os.makedirs(dir_path)
#exists_ret = os.path.exists(filepath)
try:
with open(filepath, 'a', encoding="utf-8") as fp:
fp.writelines(result)
print(f"[{current_time}] {title} 导出完成")
except Exception as e:
print(f"[{current_time}] {title} 导出失败")
def main(self):
self.get_user_info()
repos_list = self.get_repos_data()
gen_obj = self.get_article_data(repos_list)
for item in gen_obj:
self.save_article(item[0], item[1], item[2])
if __name__ == "__main__":
yq = ExportYueQueDoc()
yq.main()
6、执行导出
python yuque.py
#输出内容示例
=========== 用户信息初始化成功 ==========
[2022-12-06 22:56:55] 语雀批量导出Markdown-ken.io 写入完成
[2022-12-06 22:56:55] 浅谈软件设计模式与设计原则-ken.io 写入完成
[2022-12-06 22:56:55] 常用正则表达式收集-ken.io 写入完成
[2022-12-06 22:56:55] XShell管理远程Linux服务器安装&配置教程-ken.io 写入完成
[2022-12-06 22:56:55] Windows下Nginx安装与配置教程-ken.io 写入完成
[2022-12-06 22:56:55] Ken.io 从ASP.NET Core 3.1迁移到5.0
导出成功后可以在config.json设置的目录中看到导出结果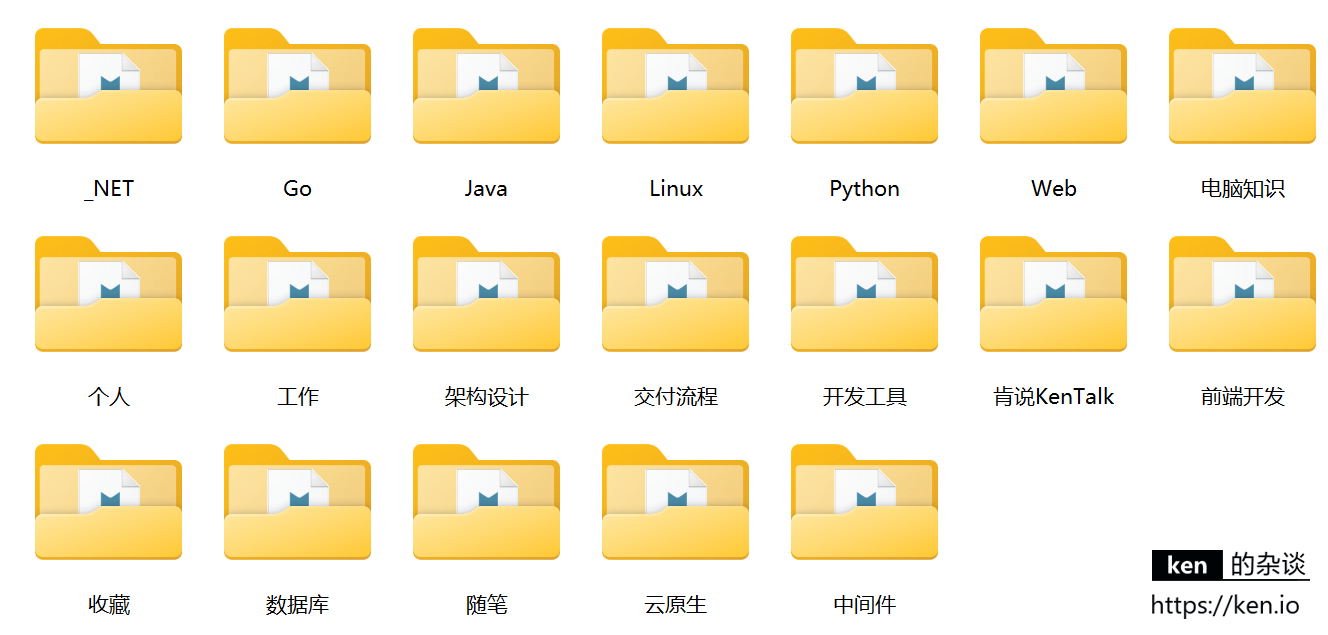
三、备注
1、可能碰到的问题
Python版本问题
python yuque.py
#输出内容
File "yuque.py", line 78
dir_path = f"{self.data_path}/{repos_name}"
^
SyntaxError: invalid syntax
这种情况可能是因为系统安装了多个Python版本,而默认的Python版本是2.x
这时候我们可以用以下命令指定Python3
#安装依赖
pip3 install requests psutil
#执行导出
python3 yuque.py
2、本文参考
https://blog.csdn.net/weixin_44797182/article/details/128059847